
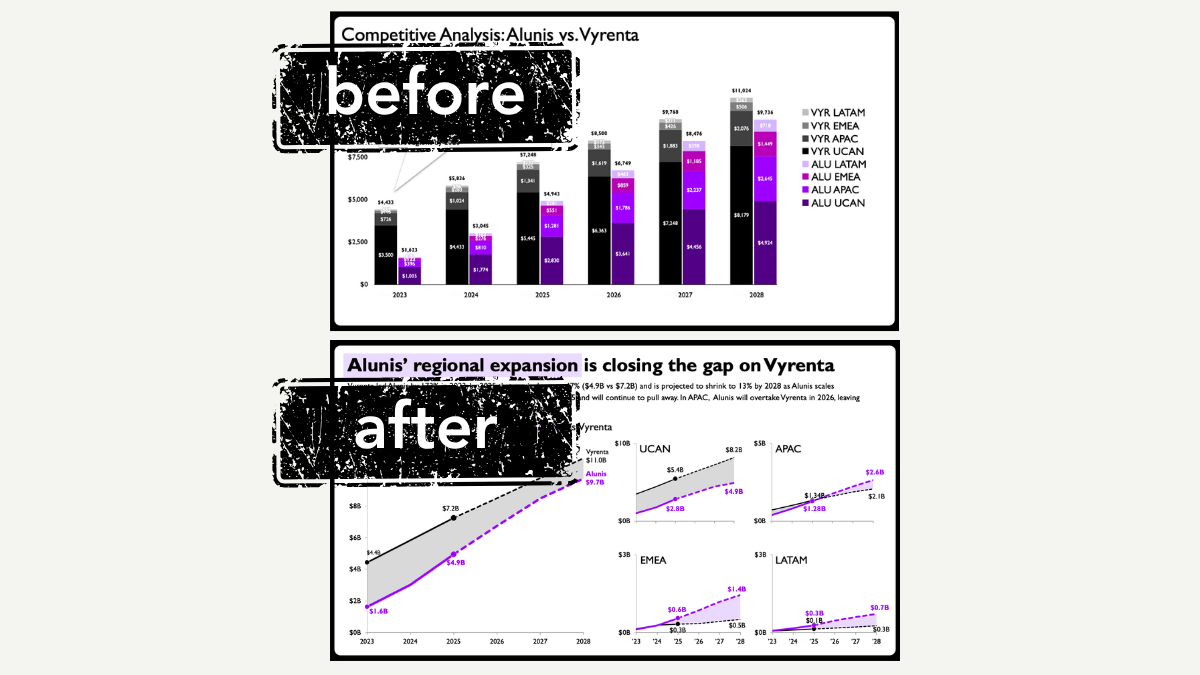
using AI without giving up control
AI-generated charts are becoming more useful. Not because they're perfect, but because they're now editable. Explore a real makeover to see how this changes the data storytelling workflow while keeping human judgment at the center.

SWD + AI: craft a story
Use AI to help you shape a stronger story—without giving up the human judgment that makes it resonate. In this post, we use storyboarding and the narrative arc to turn raw ideas into a clear plan for a data-driven presentation.

can design be taught?
Good design isn't an innate talent reserved for a lucky few. Explore ten lessons—from audience focus to visual hierarchy—that can help anyone develop a stronger design eye.

same words, different experience
Our newest data storytellers, Ryan and Alli share how joining a feedback-rich culture changed the way they hear, seek, and use feedback. Learn practical ways to build more productive feedback conversations for yourself and your team.

expanding access to data storytelling
Strong data storytelling skills can help organizations increase their impact and drive positive change. Through SWD Reach, we're making our flagship workshop more accessible to nonprofits, schools, and other mission-driven organizations that can put these lessons to work.
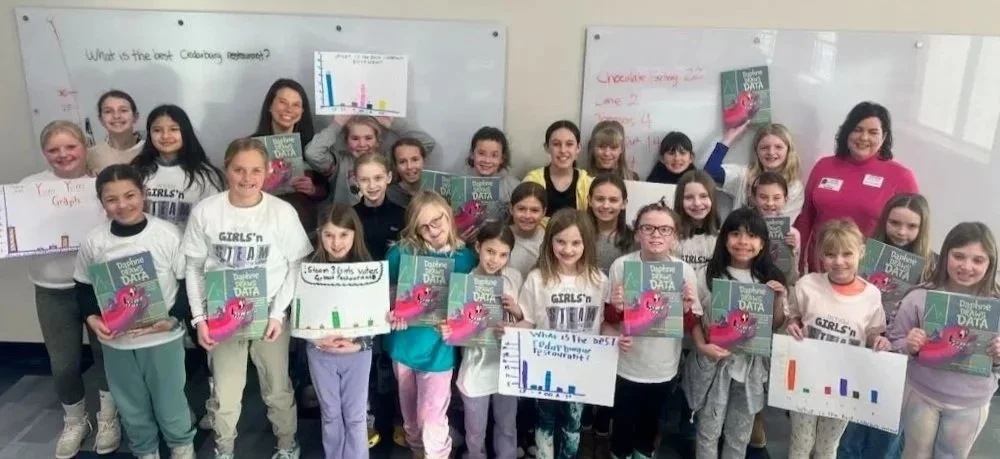
data storytelling isn’t only for grown ups
Learn how Daphne Draws Data is inspiring kids, supporting educators, and empowering volunteers to bring graphing adventures to communities around the world.

SWD + AI: start with context
The first post in our SWD + AI series explores how to use AI as a thought partner to clarify audience, stakes, and messaging before building your data communication.
structure your slides
How you structure your slides matters as much as the content you put on them. Learn go-to layouts for building slides that work whether you're presenting live or letting them stand alone.
#SWDchallenge: human + AI
Explore how human and AI can work together to create more effective data communication. This month’s challenge invites you to experiment, think critically, and share your learnings.